|
I've now talked to many people who think that causal states (minimal sufficient statistics of prediction) and epsilon-Machines (the hidden Markov models that are built from them) are niche. I would like to argue that causal states are useful. To understand their utility, we have to understand a few unfortunate facts about the world. 1. Take a random time series, any random time series, and ask if the process it comes from is Markovian or order-R Markov. Generically, no. Even if you look at a pendulum swinging, if you only take a picture every dt, you're looking at an infinite-order Markov process. Failure to understand that you need the entire past of the input to estimate the angular velocity of that pendulum results in a failure to infer the equations of motion correctly. Another way of seeing this: most hidden Markov models that generate processes will generate an infinite-order Markov process. So no matter what way you slice it, you probably need to deal with infinite-order Markov processes unless you are very clever with how you set up your experiments (e.g., overdamped Langevin equations as the stimulus). 2. Causal states are no more than the minimal sufficient statistics of prediction. They are a tool. If they are unwieldy because the process has an uncountable infinity of them-- which is the case generically-- we still have to deal with them, potentially. In truth, you can approximate processes with an infinite number of causal states by using order-R Markov approximations (better than their Markov approximation counterparts) or by coarse-graining the mixed state simplex. 3. This is less an unfortunate fact and more just a rejoinder to a misconception that people seem to have: epsilon-Machines really are hidden Markov models. To see this, check out the example below. If you see a 0, you know what state you're in, and for those pasts that have a 0, the hidden states are unhidden, allowing you to make predictions as well as possible. But if you see only 1's, then you have no clue what state you're in-- which makes the process generated by this epsilon-Machine an infinite-order Markov process. These epsilon-Machines are the closest you can get to unhidden Markov models, and it's just a shame that usually they have an infinite number of states. 4. This is a conjecture that I wish somebody would prove: that the processes generated by countably infinite epsilon-Machines are dense in the space of processes. 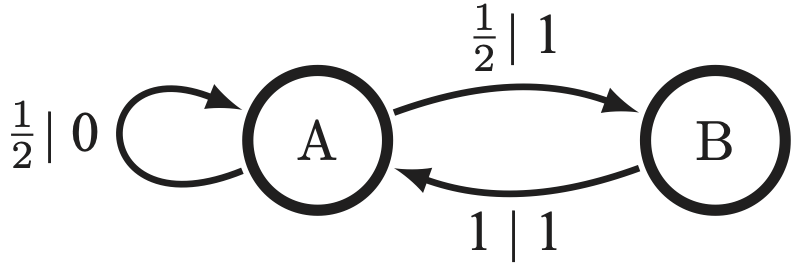 So if we want to predict or calculate prediction-related quantities for some process, it is highly likely that the process is infinite-order Markov and has an uncountable infinity of causal states. What do we do? There are basically two roads to go down, as mentioned previously. One involves pretending that the process is order-R Markov with large enough R, meaning that only the last R symbols matter for predicting what happens next. The other involves coarse-graining the mixed state simplex, which works perfectly for the infinite-order Markov processes generated by hidden Markov models with a finite number of causal states. Which one works better depends on the process. That being said, here are some benefits to thinking in terms of causal states: 1. Model inference gets slightly easier because there is, given the starting state, only one path through the hidden states for a series of observations for these weird machines. This was used to great effect here and here, and to some effect here. 2. It is easy to compute certain prediction-related quantities (entropy rate, prediction information curves) from the epsilon-Machine even though it's nearly impossible otherwise, as is schematized in the diagram below. See this paper and this paper for an example of how to simplify calculations by thinking in terms of causal states. 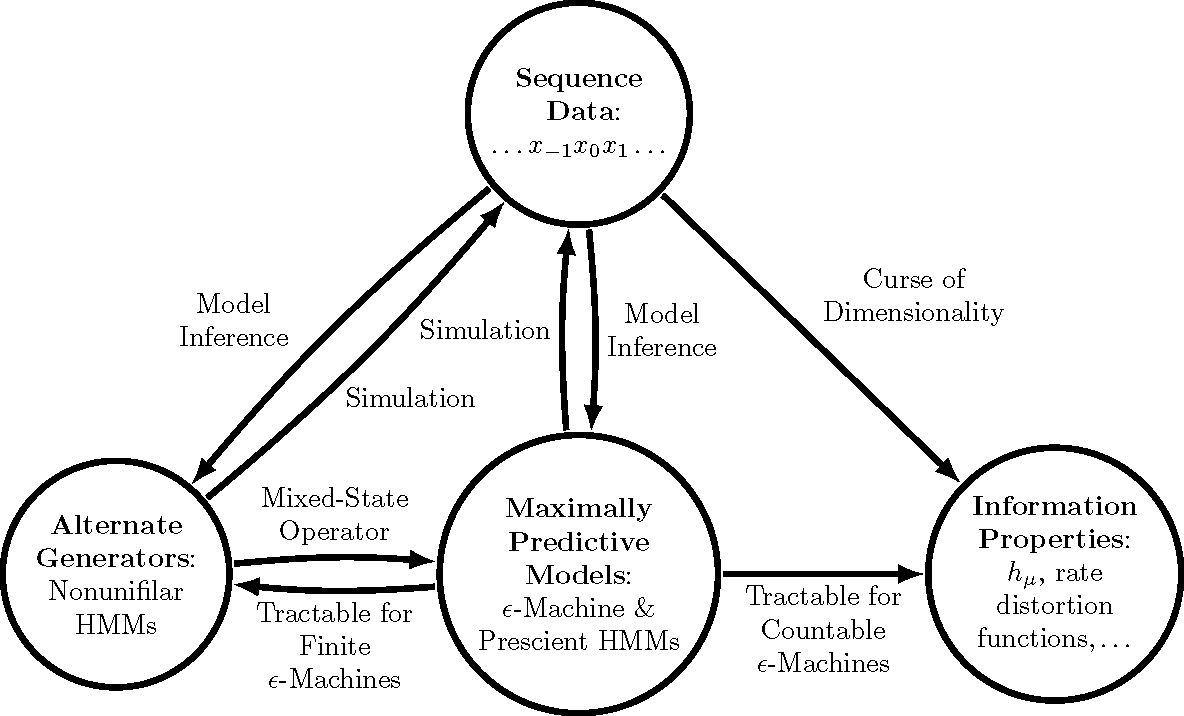
0 Comments
|
AuthorWrite something about yourself. No need to be fancy, just an overview. Archives
May 2024
Categories |
 RSS Feed
RSS Feed